作者Satoman (沙陀曼)
看板C_Chat
標題Re: [閒聊] 因為用了浮水印 追蹤少了1000人
時間Fri Nov 15 23:04:04 2024
※ 引述《mizuarashi (米茲阿拉西)》之銘言:
: 推特上有個日本繪師最近也用了浮水印,但用了之後追蹤直接少了1000多人。
: https://i.imgur.com/knrf5g0.jpeg
: 因為他的浮水印是他家的貓
雖然知道這位畫師應該是想玩梗和酸馬斯克,但是這方法建議別用。
不能說完全無效,但是可以說微乎其微。
AI對於圖片中的異物,也就是浮水印、簽名、商標等等有很高的辨識力,
若是再加上提詞區分的話,浮水印基本上是擺好看的。
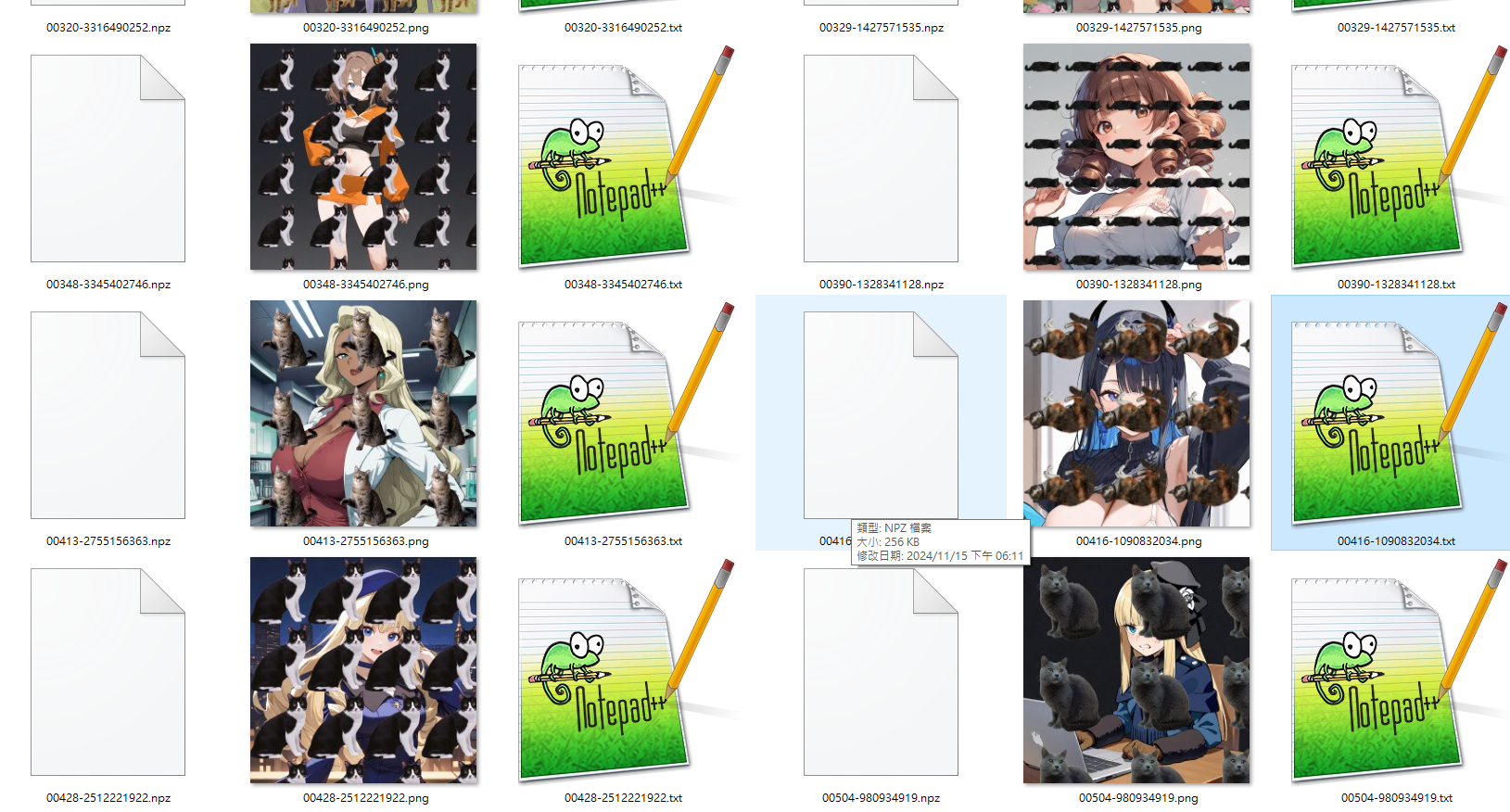
我就直接用這案例,做個簡單的實驗當栗子。
我模仿這位畫師,用素材網站隨便抓來的貓貓圖蓋在圖片上做一個風格Lora模型訓練集,
底圖則是我測試時用同一個模型產生,風格類似的AI廢圖,大概長這樣:
https://iili.io/2AGKQgs.png
模擬一下實際使用情況,
訓練的底模用Illustrious XL,然後再用noobAI來生圖。
先測試一下沒套風格模型,
也沒有任何品質提詞(Masterpiece等等)和負面提詞生圖的結果。
https://iili.io/2AGBD7a.png
然後我們套上用貓貓圖訓練的風格Lora模型後,用相同的提詞跑第一張。
https://iili.io/2AGC4vs.png
欸,貓貓出來了。你看,很有用吧這招。
等等,相同參數我們再跑個幾張。
https://iili.io/2AGx9hx.png
https://iili.io/2AGoyIj.png
https://iili.io/2AGxHLQ.png
貓貓沒有每張圖都出現,實際上是跑了30張圖出現了8張貓貓圖。
約1/3。
https://iili.io/2AGIBWv.png
1/3看起來已經很高了吧?是不是達到汙染的目的了?
那我們加上品質提詞試試看,就用我平常用的這組。
正面是
masterpiece,best quality,high quality, good quality very aesthetic,absurdres,
負面是
(bad quality,low quality,worst quality:1.4),bad anatomy,signature,watermark,
backlighting,shaded face,
產生的結果長這樣:
https://iili.io/2AGAmp1.png
https://iili.io/2AGYP9V.png
https://iili.io/2AGaKVn.png
https://iili.io/2AGaFoX.png
還是有浮貓印,但是已經降低到30張只剩兩張了。
而且如果有觀察降躁細節的話,有時還可以看到貓貓被AI逐漸分解成背景的過程。
最後一步,在訓練打標時有兩個敏感度特別高的提詞,分別是cat和too many。
我們把它丟到負面提詞去做區隔。
https://iili.io/2AG182s.png
貓貓……倒了。
只要以簡單以提詞處理區隔,
這30張乍看之下被浮貓印蓋得七零八落的圖片也能被訓練成一個正常的風格Lora模型。
有用,但就只有那麼一點點。
這個Lora就只是不太能生成和貓有關的圖片而已。
或許浮貓印還可以再強化,
例如分布隨機化、加入狗狗鳥鳥龜龜兔兔等等,應該能讓AI更混淆。
但扣除怒噴馬斯克,引導粉絲去bluesky的宣示意味之外,
真的有必要花時間做這些事嗎?
好像沒有。
第一點。
馬斯克就算用X上的資料訓練AI,那這些浮貓印圖片也只會是數億張圖片中的少少幾張,
在沒有特別針對學習(應該沒有那麼閒)的情況,
不管有貓沒貓都不會在成品有任何肉眼可辨認的影響。
(而且我不相信只靠X就能搞出能用的模型,大概最終還是得去找類似LAION的資料庫 ==)
第二點。
不是只有X在爬資料訓練模型,他肯告訴你還算好的。
沒有公開資料來源,連訓練方都不知道自己到底拿了啥在訓練的大模型比比皆是。
以上這還是用爬蟲當前提。
假設有人想訓練這位畫師的畫風模型Lora,那可能連爬蟲都不用,
直接去bluesky拿圖就好。
第三點,也是最重要的一點。
ACG畫風的AI模型的直接資料來源不是推特或其他社交平台,
甚至有時候連Pixiv或deviantart等等投稿網站都不是。
事實上,自從NovelAI用爬蟲爬了某個盜圖網站訓練出第一款普及的ACG畫風模型以來,
那個盜圖網站就一直是所有大型ACG風格模型的主要學習對象。
現今被稱為「咒語」的標籤式提詞其實就是源自該網站對於圖片的詳細分類標籤。
甚至,由於該網站有清楚的標示角色、作品、畫師等資訊,
所以現今模型經過學習後也可以單純靠輸入上述資訊的提詞來生成標籤標註的圖片。
至於盜圖網站的圖片哪來的?
很單純,就只是使用者從各處的網站右鍵另存檔案再上傳,然後再人工打上分類標籤。
該網站也很清楚的將AI圖從圖庫中區隔開來,
所以一直被視為「清潔」又有效的訓練資料來源。
所以只要圖片有上傳到網路上,就有可能被人上傳到該網站上,
然後再被AI模型所學習。
那該怎麼辦?浮水印又沒啥用,難道畫師就沒有反制的方法嗎?
也不能說沒有,其實可以只上傳在訓練時會被剃除的圖片來防爬蟲。
因為大模型不可能像我搞Lora一樣手搓調整訓練集,
所以勢必得用自動縮放調整圖片大小和比例。
這其中就有一些圖片被認為無益或是會污染資料而被剃除。
以能模仿畫師畫風的開源模型Illustrious-XL來講,
他們公開的paper其實有講了有三類圖片會從訓練集中被剃除。
1.太小的圖片,未滿768*768。
2.太大的圖片,超過4000萬像素。
3.比例太極端的圖片,超過1:10。
簡單來講,太小AI可能不要,太大AI可能也不要,太長太寬AI也不要。
在我的認知無誤的前提下,
與其上浮水印,不如單純不要公開大小為768*768以上的圖片就好。
由於AI訓練的解析度一直在拉高,已經從最早的512*512一路飆到有人在搞2048*2048,
因此避免上傳大圖理論上可以防一些爬蟲。
或者上傳版面尺寸比例超過1:10的圖片,主要視覺部分不變,
其他版面拉空的部分看要塞貓貓還是狗狗,這樣目前應該也能防一些爬蟲。
當然,以上這都是防爬蟲不防人手。
講白點,就像看到好圖右鍵一樣。
真的像盜圖網站那樣用人力蒐集資料,或是爬蟲飢不擇食的話那是不能防的。
只是上述的圖片處理方法理論上可以勸退,或污染某些比較隨興的Lora製作者的成果。
--
(と・てノ) 翼龍欸
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 1.163.176.215 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/C_Chat/M.1731683047.A.C7D.html